

Datamodenhed til Microsoft Fabric
Datamodenhed
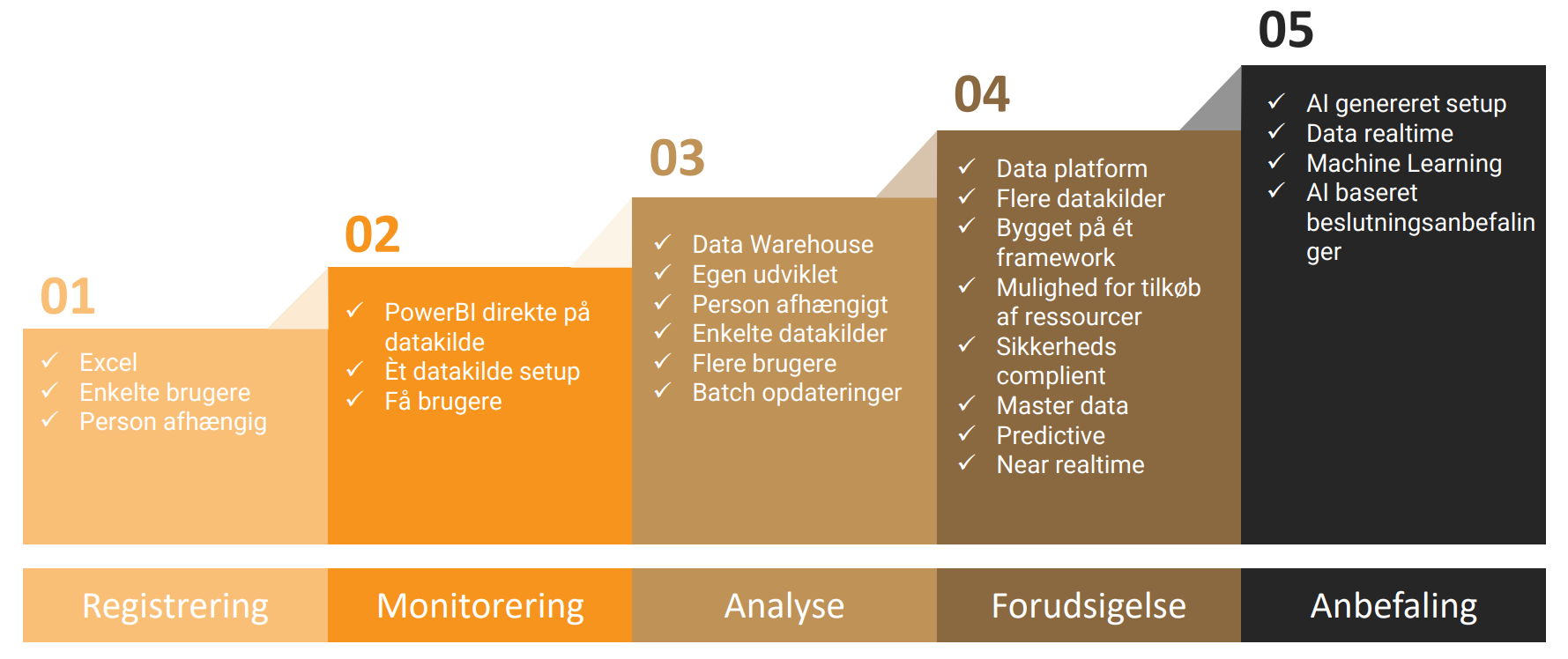
Modellen består af fem trin – fra manuel Excel-rapportering til fuldt integreret og datadrevet beslutningstagning med avanceret analyse og AI. Hvert trin beskriver de typiske kendetegn og udfordringer, man møder undervejs, samt hvad der skal til for at rykke videre.
Datamodenhed handler ikke kun om teknologi – men om struktur, ansvar og forankring. Jo bedre I forstår jeres nuværende position, desto nemmere bliver det at tage det næste skridt.
Registrering
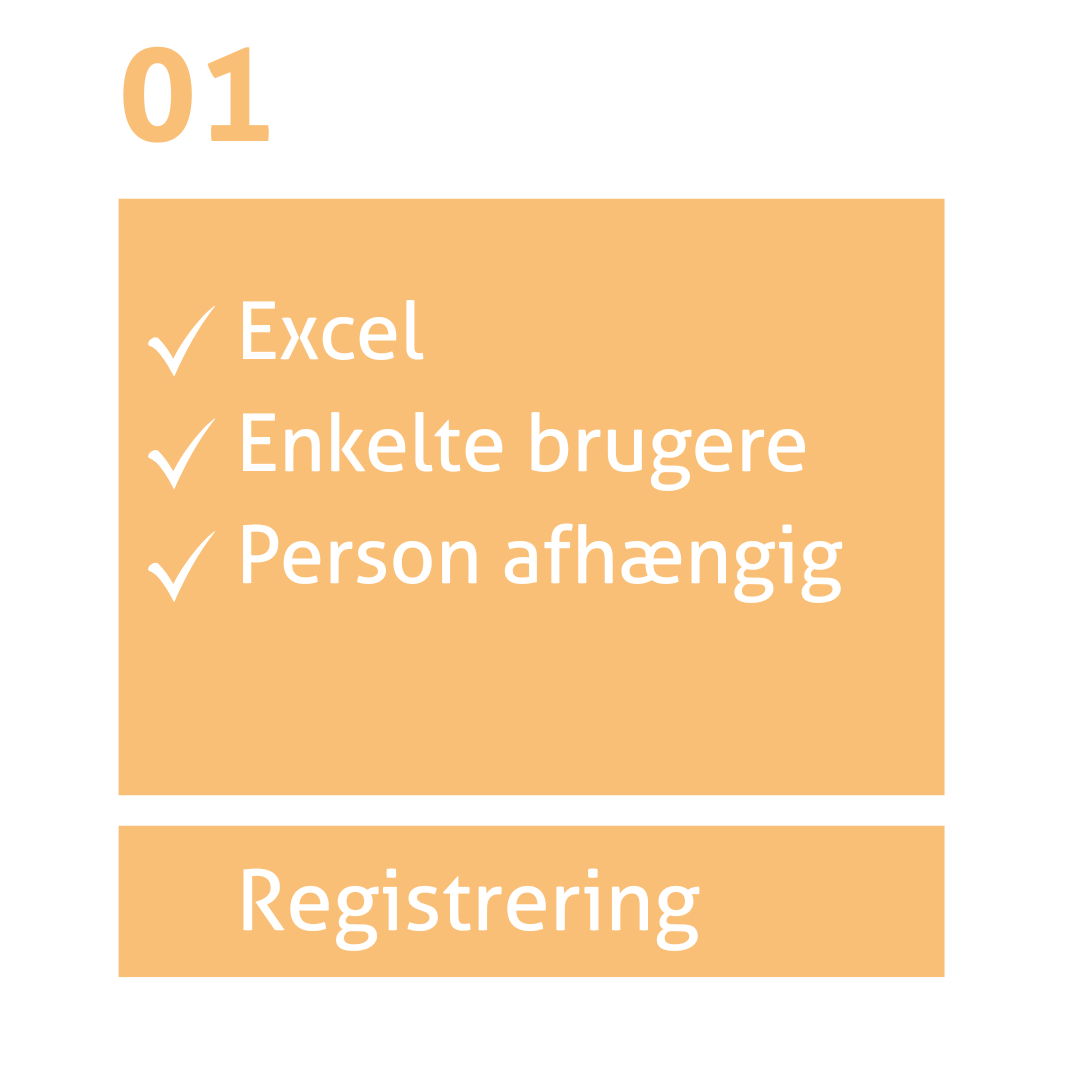
I registreringsstadiet foregår rapportering primært i Excel uden fælles struktur. Processerne er manuelle og personafhængige, hvilket giver lav datakvalitet og høj risiko for fejl.
Deling af data er usikker, og data bruges sjældent som grundlag for beslutninger.
Monitorering
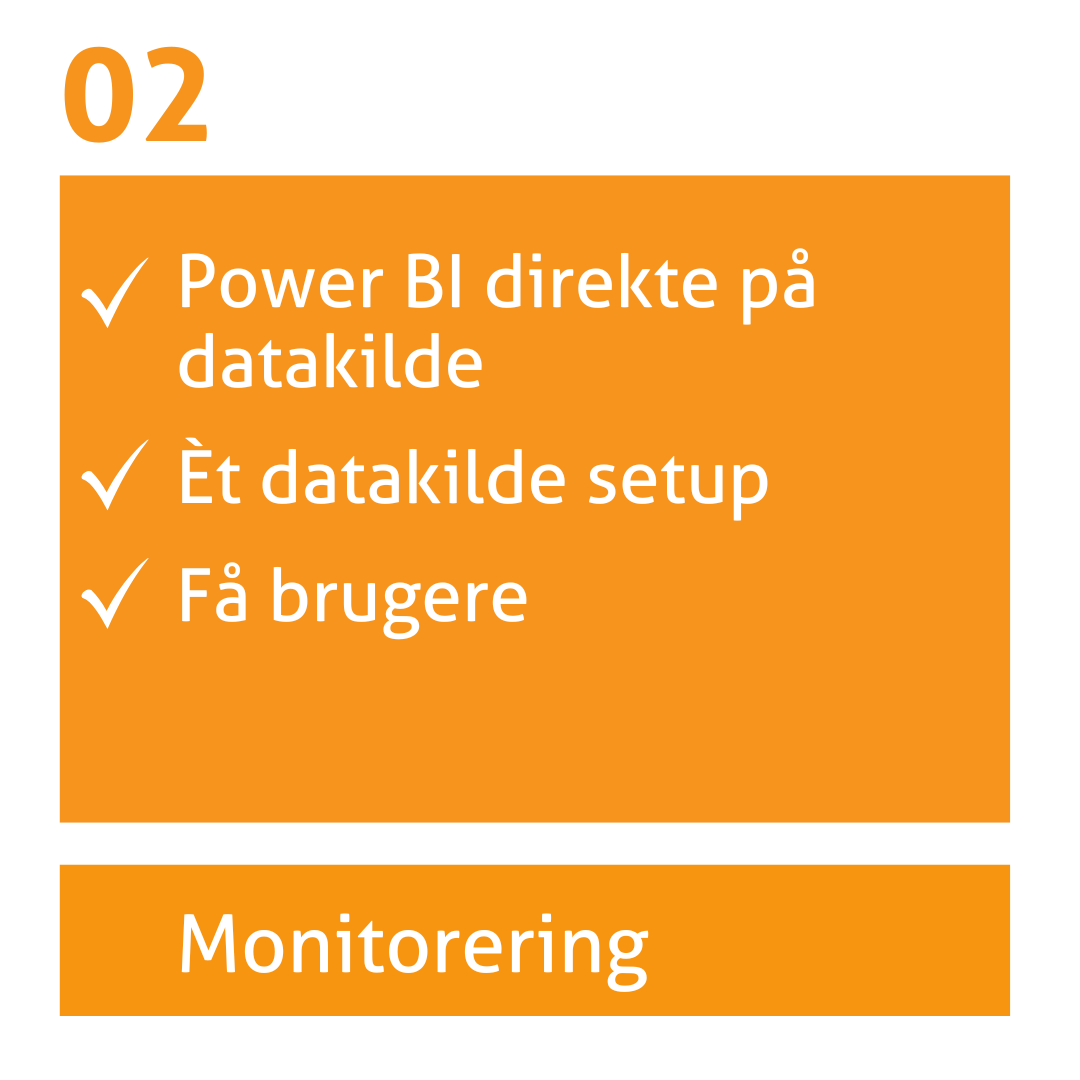
I monitoreringsstadiet bruges Power BI, men løsningen bygger typisk direkte på én datakilde uden fælles struktur.
Rapporteringen er begrænset, manuelle opdateringer dominerer, og der mangler ensartede definitioner. Det gør det svært at skalere og udvide løsningen.

Analyse
I analysestadiet kombineres flere datakilder, og arbejdet bliver mere analytisk. Der begynder at opstå struktur, men en samlet dataplatform og governance mangler.
Kompleksiteten vokser, og det bliver sværere at sikre ensartethed, styring og skalering.

Forudsigelse
I beslutningsstadiet er en central dataplatform etableret, og data håndteres struktureret og sikkert. Rapportering er automatiseret og forankret i ledelsen, og governance fungerer i praksis.
Udfordringen er nu at bevare overblik i en kompleks løsning og understøtte avancerede analyser – men AI og machine learning er endnu ikke i spil.

Anbefaling
I anbefalingsstadiet er BI fuldt integreret i forretningen, og beslutninger understøttes af realtidsdata, AI og machine learning.
Organisationen modtager automatiske anbefalinger, og governance fungerer effektivt.
Fokus ligger nu på at håndtere høj kompleksitet og imødekomme krav til performance, selvbetjening og tæt samarbejde mellem data og forretning.
Kontakt os angående Microsoft Fabric
Har du spørgsmål du brænder inde med, så hiv fat i os!
Det kan være angående mulighederne ved Fabric, fundamentet for en datadreven strategi, eller noget helt tredje.

Kontakt formular
Ved at udfylde formularen giver du samtykke til at modtage yderligere informationer fra os. Du vil altid kunne afmelde informationer fra Accobat med et enkelt klik i tilsendte mails. Læs mere om vores persondatapolitik.


